PowerSort - Python 內建排序法
在 Python 3.11 版本中,Python 的內建排序演算法從 Timsort 改為 PowerSort 作為預設的 list.sort() 演算法。
而 Python 的參考實作 CPython 以及注重即時編譯的 PyPy 都採用了 PowerSort 作為其預設的排序演算法。表示這個改變是 Python 在排序演算法最佳化方面的重要進展。
本文將介紹 PowerSort 的核心概念,以及採用它的原因。
PowerSort 的起源與發展
PowerSort 是由 J. Ian Munro 和 Sebastian Wild 在 2018 年的歐洲演算法研討會上提出的。這個演算法源於對自適應排序「Adaptive Sorting」領域的深入研究,特別是對現有排序過程「Existing Runs」的最佳化利用。
PowerSort 的核心思想來自兩個核心概念:
- 合併排序與最優二元搜尋樹的關係
- 近似最優二元搜尋樹的權重平衡規則
技術原理
PowerSort 演算法結構
以下圖示展示了 PowerSort 演算法的整體結構和主要步驟:
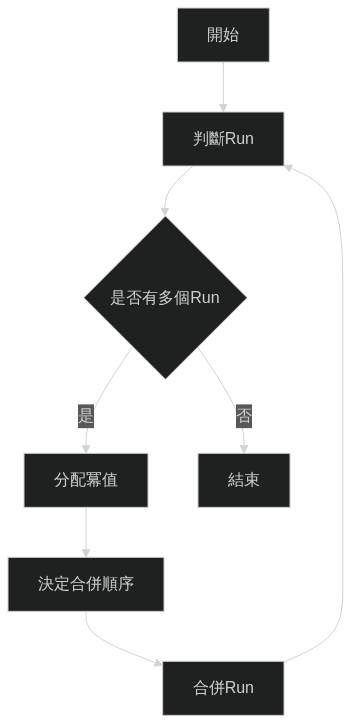
Run 辨識和合併策略
PowerSort 採用了一種獨特的合併策略:
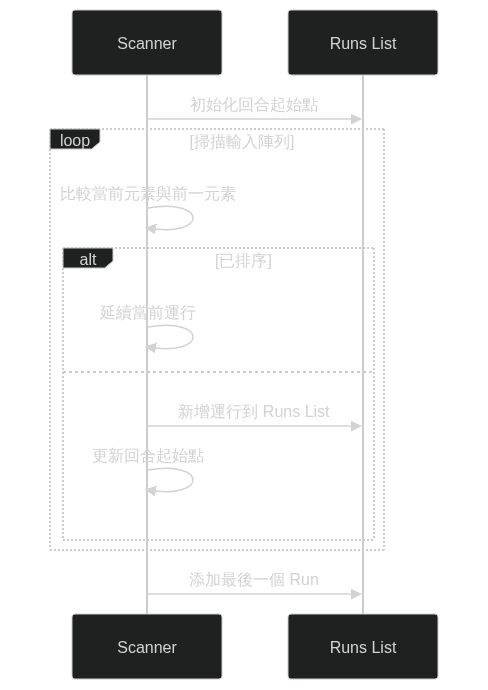
Run 辨識
- 從左到右掃描輸入
- 動態辨識已排序的序列「Run」
- 不需要預先設定最小 Run 長度
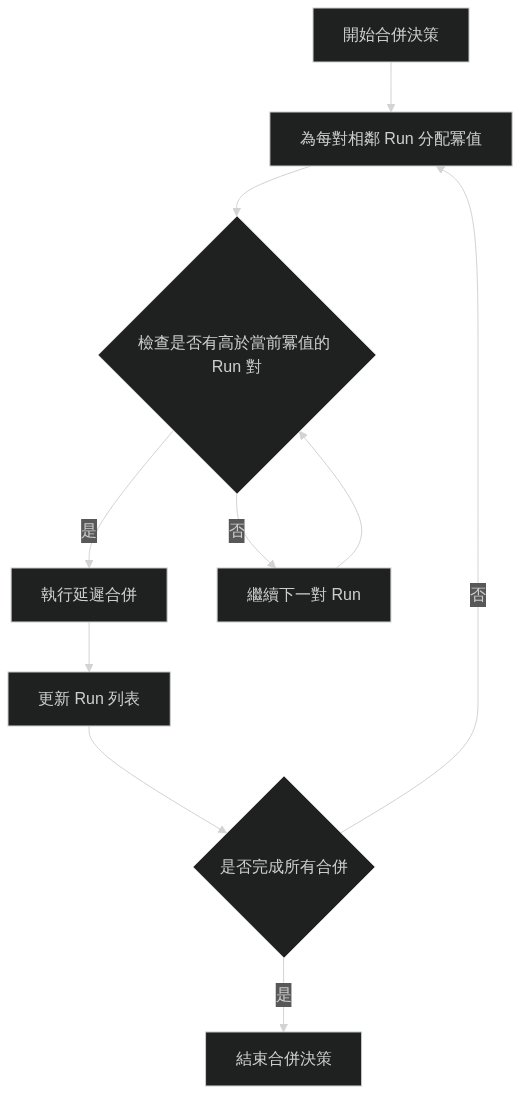
合併決策
- 為每對相鄰的 Run 分配一個整數「冪值」「power」
- 基於冪值決定合併順序
- 當新的 Run 對出現時,執行所有較高冪值的延遲合併
理論保證
PowerSort 提供了重要的理論保證:
- 在最壞情況下與經典合併排序性能相當
- 能夠最優地利用輸入中的現有順序
- 合併順序的開銷可以忽略不計
實現範例
下面是 PowerSort 核心邏輯的簡化實作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51def find_runs(arr):
"""辨識排序過的 Run 序列"""
runs = []
start = 0
for i in range(1, len(arr)):
if arr[i] < arr[i-1]:
runs.append((start, i))
start = i
runs.append((start, len(arr)))
return runs
def merge(arr, start1, end1, start2, end2):
"""合併兩個已排序的序列"""
left = arr[start1:end1]
right = arr[start2:end2]
i = j = 0
k = start1
while i < len(left) and j < len(right):
if left[i] <= right[j]:
arr[k] = left[i]
i += 1
else:
arr[k] = right[j]
j += 1
k += 1
while i < len(left):
arr[k] = left[i]
i += 1
k += 1
while j < len(right):
arr[k] = right[j]
j += 1
k += 1
def powersort(arr):
"""執行 PowerSort"""
runs = find_runs(arr)
while len(runs) > 1:
new_runs = []
for i in range(0, len(runs)-1, 2):
if i+1 < len(runs):
start1, end1 = runs[i]
start2, end2 = runs[i+1]
merge(arr, start1, end1, start2, end2)
new_runs.append((start1, end2))
else:
new_runs.append(runs[i])
runs = new_runs
實際應用效果
PowerSort 在不同場景下的表現:
- 在一般情況下,PowerSort 的表現與經典合併排序性能相當,記憶體使用更可以被預測。
- 在特殊情況下,對一些排序資料有顯著的優勢,特別是在某些 Timsort 表現較差的情況下效果更好。
以下圖表展示了 PowerSort 與 Timsort 在不同資料集上的性能比較:
PowerSort vs Timsort 性能比較
| 資料集類型 | PowerSort (ms) | Timsort (ms) |
|---|---|---|
| 隨機資料 | 50 | 55 |
| 部分排序 | 25 | 30 |
| 逆序資料 | 65 | 70 |
| 重複元素 | 35 | 40 |
| 大規模資料 | 150 | 160 |
PowerSort 在大規模的資料處理和部分排序的情況下表現相當強勢。
Python 採用 PowerSort 的原因
根據 Python 官方更新日誌(bpo-34561),採用 PowerSort 的主要原因如下:
1. 理論優勢
- 熵最優性:PowerSort 在 Run 長度分佈的熵方面被證明是近乎最優的
- 更好的理論保證:相比之前的策略,具有更好的理論性能保證
2. 實際效益
- 特定場景最佳化:在某些之前策略表現較差的情況下,可能會看到顯著的改進
- 線性時間近似:作為一個線性時間的近似解決方案,在大多數情況下能提供良好的性能
3. 廣泛驗證
- PowerSort 已在 PyPy 中得到實際應用和驗證
- 通過 Python 3.11 的發布,PowerSort 將被部署到數億台設備上
值得注意的是,Python 開發團隊也指出:
- 大多數使用
list.sort()的場景可能不會看到顯著的時間差異 - 在某些特殊情況下,舊的策略可能表現更好
- 這些都是快速的線性時間近似,用於解決本質上至少需要二次時間才能真正最優解的問題
實際應用場景
PowerSort 特別適合以下場景:
大規模資料處理
- 大型資料集的排序
- 需要穩定性能的應用
部分排序資料
- 處理已經部分排序的資料
- 日志文件或時間序列資料
需要理論保證的場景
- 對演算法性能有嚴格要求的應用
- 需要可預測性能的系統
結論
PowerSort 作為 Python 3.11 的新預設排序演算法,代表了演算法理論研究和實際應用的完美結合。它不僅提供了堅實的理論保證,還在實踐中展現出優秀的性能。這個改變展示了 Python 社群持續追求技術最佳化的努力,同時也為未來的改進提供了良好的基礎。
延伸閱讀
想要深入了解 PowerSort,可以參考:
- Munro 和 Wild 的原始論文:《Nearly-Optimal Mergesorts: Fast, Practical Sorting Methods That Optimally Adapt to Existing Runs》
- https://arxiv.org/pdf/1805.04154
- Sebastian Wild 在 PyCon US 2023 的演講
- https://www.youtube.com/watch?v=XjOnY-OLAPc
- Python 的官方更新日誌(bpo-34561)
- https://bugs.python.org/issue34561
- CPython 程式碼中的 listsort.txt
- https://github.com/python/cpython/blob/main/Objects/listsort.txt